ansheng’s blog!
通过Cephadm部署容器化Ceph集群
Cephadm是通过容器(Docker)来实现集群的部署,相对于手动部署和ansible等版本,容器更简单且不会污染系统环境,Cephadm是Ceph版本v15.2.0(Octopus)中的新增功能,并且不支持旧版本的Ceph。
环境
| 主机名 | 系统 | IP | OSD盘 |
|---|---|---|---|
| node0 | CentOS 8 | 192.168.200.100 | sdb、sdc、sdd |
| node1 | CentOS 8 | 192.168.200.101 | sdb、sdc、sdd |
| node2 | CentOS 8 | 192.168.200.102 | sdb、sdc、sdd |
初始化
系统环境
$ cat /etc/redhat-release
CentOS Linux release 8.3.2011
$ whoami
root
以下的操作在每台主机上操作
$ dnf install vim net-tools telnet -y
$ dnf update -y
$ systemctl disable --now firewalld
$ setenforce 0
$ sed -i s/SELINUX=enforcing/SELINUX=permissive/g /etc/selinux/config
- 更新hosts文件
$ cat >> /etc/hosts <<EOF
192.168.200.100 node0
192.168.200.101 node1
192.168.200.102 node2
EOF
- 配置时间同步
$ dnf install -y chrony
$ systemctl enable --now chronyd
- Docker
安装Docker请参考CentOS安装Docker和Docker-componse这篇文章
- 重启系统
$ reboot
安装Cephadm
cephadm命令有两种安装方式,选择任何一种适合的方式在全节点上面进行安装
基于curl的安装方法
下载基于pacific版本的ceph
$ curl --silent --remote-name --location <https://github.com/ceph/ceph/raw/pacific/src/cephadm/cephadm>
添加可执行权限
$ chmod +x cephadm
放到命令添加到PATH目录下
$ mv cephadm /usr/sbin/cephadm
特定发行版的安装方法
- Ubuntu
$ apt install cephadm -y
- RHEL系列
$ dnf install cephadm -y
创建集群
在node0上面运行以下命令,该命令将创建群集的第一个monitor daemon,并且该Mon守护程序需要一个IP地址,你必须将Ceph群集的第一个主机的IP地址传递给命令
$ cephadm bootstrap --mon-ip 192.168.200.100
......
# 创建成功之后返回如下信息
Ceph Dashboard is now available at:
URL: <https://node0:8443/>
User: admin
Password: evy9q5m77k
You can access the Ceph CLI with:
sudo /usr/sbin/cephadm shell --fsid 4be082ac-a125-11eb-bdb1-0800278a6302 -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
Please consider enabling telemetry to help improve Ceph:
ceph telemetry on
For more information see:
<https://docs.ceph.com/docs/pacific/mgr/telemetry/>
Bootstrap complete.
该命令将:
- 在node0节点上为Ceph集群创建
Mon和Mgr服务 - 生成一个新的SSH Key,并将其添加到root用户的/root/.ssh/authorized_keys文件中
- 将默认的配置文件写入/etc/ceph/ceph.conf
- 创建client.admin密钥的副本到/etc/ceph/ceph.client.admin.keyring
- 将public key写入到/etc/ceph/ceph.pub
如果你通过Chorme打开管理后台网址,提示SSL错误并无法继续时候,请在浏览器页面任何位置输入thisisunsafe字符串就可以访问了。。。。。
Ceph CLI
通过如下命令可以进入ceph shell
$ cephadm shell
Inferring fsid 4be082ac-a125-11eb-bdb1-0800278a6302
Inferring config /var/lib/ceph/4be082ac-a125-11eb-bdb1-0800278a6302/mon.node0/config
Using recent ceph image ceph/ceph@sha256:9b04c0f15704c49591640a37c7adfd40ffad0a4b42fecb950c3407687cb4f29a
# 进入之后可以发现左边出现ceph,类似python的venv
[ceph: root@node0 /]#
查看集群状态
[ceph: root@node0 /]# ceph -s
cluster:
id: 4be082ac-a125-11eb-bdb1-0800278a6302
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum node0 (age 11m)
mgr: node0.zwhfrl(active, since 10m)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
查看Ceph版本
[ceph: root@node0 /]# ceph -v
ceph version 16.2.0 (0c2054e95bcd9b30fdd908a79ac1d8bbc3394442) pacific (stable)
以后我们操作ceph的时候都是在ceph shell环境中运行的.
- 设置集群默认的Mon数量
一个典型的Ceph集群具有三个或五个Mon守护程序,这些守护程序分布在不同的主机上,默认情况下,Cephadm将设置5个Mon节点,但是本篇文章只有两个,且另外一个是后面添加的,所以我们将集群Mon数量设置为默认一个即可。
$ ceph orch apply mon 1
添加节点
在添加之前我们先查看现在集群中有多少节点
$ ceph orch host ls
HOST ADDR LABELS STATUS
node0 node0
在node0节点上将/etc/ceph/ceph.pub复制到node1和node2节点的root用户中
$ ssh-copy-id -f -i /etc/ceph/ceph.pub root@node1
$ ssh-copy-id -f -i /etc/ceph/ceph.pub root@node2
告诉Ceph,新节点是集群的一部分
$ ceph orch host add node1 --labels=mon
$ ceph orch host add node2 --labels=osd
查看现有的主机数量
$ ceph orch host ls
HOST ADDR LABELS STATUS
node0 node0
node1 node1
node2 node2
通过管理后台页面也可以查看现有主机数量
主机标签
添加标签可以更方便我们进行识别
- 在添加主机时通过–labels添加
$ ceph orch host add my_hostname --labels=my_label1
$ ceph orch host add my_hostname --labels=my_label1,my_label2
- 为现有的主机添加
$ ceph orch host label add node2 osd
查看主机数量
$ ceph orch host ls
HOST ADDR LABELS STATUS
node0 node0
node1 node1
node2 node2 osd
- 要删除标签,请运行:
$ ceph orch host label rm node2 osd
查看主机数量
$ ceph orch host ls
HOST ADDR LABELS STATUS
node0 node0
node1 node1
node2 node2
Mon节点
我们将node1节点部署为监控节点
$ ceph orch apply mon node1
添加完成之后在挂了后台可以看到Monitors是2 (quorum 0, 1)
- 通过标签的方式批量添加Mon节点
如果你有一组服务器需要批量更改为Mon节点,你可以先给他们添加一个mon标签
$ ceph orch host label add host1 mon
$ ceph orch host label add host2 mon
$ ceph orch host label add host3 mon
$ ceph orch host ls
然后执行以下指令
$ ceph orch apply mon label:mon
OSD节点
我们需要在三个节点上面把设备/dev/sdb、/dev/sdc\\、/dev/sdd这三块硬盘添加到存储中
- 查看设备列表
$ ceph orch device ls
Hostname Path Type Serial Size Health Ident Fault Available
node0 /dev/sdb hdd VB5b5f7d0e-558d5d93 5368M Unknown N/A N/A Yes
node0 /dev/sdc hdd VB7842f9f2-f8788815 5368M Unknown N/A N/A Yes
node0 /dev/sdd hdd VBf036e995-aa0c6c8e 5368M Unknown N/A N/A Yes
node1 /dev/sdb hdd VB5736c5bf-b97be4c7 5368M Unknown N/A N/A Yes
node1 /dev/sdc hdd VB7774db3b-947fae30 5368M Unknown N/A N/A Yes
node1 /dev/sdd hdd VB13ed386a-3c527f60 5368M Unknown N/A N/A Yes
node2 /dev/sdb hdd VB60f28c84-91e6e937 5368M Unknown N/A N/A Yes
node2 /dev/sdc hdd VB0d66207b-18d1ff37 5368M Unknown N/A N/A Yes
node2 /dev/sdd hdd VBff02aeca-45540d70 5368M Unknown N/A N/A Yes
你也可以传递--hostname参数只查看某台主机的设备
$ ceph orch device ls --hostname=node0
Hostname Path Type Serial Size Health Ident Fault Available
node0 /dev/sdb hdd VB5b5f7d0e-558d5d93 5368M Unknown N/A N/A Yes
node0 /dev/sdc hdd VB7842f9f2-f8788815 5368M Unknown N/A N/A Yes
node0 /dev/sdd hdd VBf036e995-aa0c6c8e 5368M Unknown N/A N/A Yes
- 部署OSD
添加node0节点上面的/dev/sdb设备
$ ceph orch daemon add osd node0:/dev/sdb
添加将所有主机的所有可用设备
$ ceph orch apply osd --all-available-devices
运行以上命令后,如果集群检测到新设备将自动添加到OSD,要禁用在可用设备上自动创建OSD的功能,请使用以下unmanaged参数:
如果要避免此行为(禁用可用设备上的OSD自动创建),请使用unmanaged参数:
$ ceph orch apply osd --all-available-devices --unmanaged=true
-dry-run参数在不实际创建OSD的情况下呈现将要发生的情况的预览
$ ceph orch apply osd --all-available-devices --dry-run
NAME HOST DATA DB WAL
all-available-devices node1 /dev/vdb - -
all-available-devices node2 /dev/vdc - -
all-available-devices node3 /dev/vdd - -
- 查看已挂载的OSD列表
$ ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.04408 root default
-3 0.01469 host node0
0 hdd 0.00490 osd.0 up 1.00000 1.00000
1 hdd 0.00490 osd.1 up 1.00000 1.00000
4 hdd 0.00490 osd.4 up 1.00000 1.00000
-5 0.01469 host node1
2 hdd 0.00490 osd.2 up 1.00000 1.00000
5 hdd 0.00490 osd.5 up 1.00000 1.00000
7 hdd 0.00490 osd.7 up 1.00000 1.00000
-7 0.01469 host node2
3 hdd 0.00490 osd.3 up 1.00000 1.00000
6 hdd 0.00490 osd.6 up 1.00000 1.00000
8 hdd 0.00490 osd.8 up 1.00000 1.00000
- 激活现有的OSD
如果重新安装了主机的操作系统,则需要再次激活现有的OSD
$ ceph cephadm osd activate <host>...
CephFS
CephFS需要一个或多个MDS守护程序
$ ceph fs volume create myfs --placement="node0,node1"
查看创建的CephFS
$ ceph fs ls
name: myfs, metadata pool: cephfs.myfs.meta, data pools: [cephfs.myfs.data ]
- 使用CephFS
在node2节点上面通过mount的方式将CephFS挂载到本地
创建挂载目录
$ mkdir /mnt/cephfs
在node0节点上面查看admin的key
$ cat /etc/ceph/ceph.keyring
[client.admin]
key = AQBNMX5gHUXtIRAAV1bQw+xi1YZ1fOSNZisr2A==
通过mount挂载
$ mount -t ceph 192.168.200.100:6789:/ /mnt/cephfs -o name=admin,secret=AQBNMX5gHUXtIRAAV1bQw+xi1YZ1fOSNZisr2A==
写入/etc/fstab自动挂载
$ umount /mnt/cephfs
$ vim /etc/fstab
192.168.200.100:6789:/ /mnt/cephfs ceph name=admin,secret=AQBNMX5gHUXtIRAAV1bQw+xi1YZ1fOSNZisr2A==,noatime,_netdev 0 2
$ mount -a
查看挂载点
$ df -h | grep mnt
192.168.200.100:6789:/ 15G 0 15G 0% /mnt/cephfs
写入数据测试
$ echo ping > /mnt/cephfs/pong
$ cat /mnt/cephfs/pong
ping
RGW
通过标签将多台主机创建rgw服务
$ ceph orch host label add node0 rgw # the 'rgw' label can be anything
$ ceph orch host label add node1 rgw
查看主机标签
$ ceph orch host ls
HOST ADDR LABELS STATUS
node0 node0 rgw
node1 node1 mon rgw
node2 node2 osd
在标签为rgw的主机上面创建rgw服务,每个节点运行两个进程,端口从8000开始
$ ceph orch apply rgw foo '--placement=label:rgw count-per-host:2' --port=8000
如果你只需要在一台主机上运行RGW服务,那么只需要执行以下指令
$ ceph orch apply rgw foo
更多参数请通过如下指令查看
$ ceph orch apply rgw --help
测试
- 创建用户
$ radosgw-admin user create --uid=admin --display-name=Admin --email=admin@exampple.com
{
"user_id": "admin",
"display_name": "Admin",
"email": "admin@exampple.com",
"suspended": 0,
"max_buckets": 1000,
"subusers": [],
"keys": [
{
"user": "admin",
"access_key": "A4F6G48RZDCDX0QUP2IR",
"secret_key": "rGDnpgK05UmCBDHpO9aIvxFu3b4EMShHFyUk9WAJ"
}
],
"swift_keys": [],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"default_storage_class": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"temp_url_keys": [],
"type": "rgw",
"mfa_ids": []
}
保存access_key和secret_key,然后切换到node1主机上执行如下操作
- 安装boto3
$ pip3 install boto3
- 创建测试脚本
$ vim test.py
import boto3
access_key = 'A4F6G48RZDCDX0QUP2IR'
secret_key = 'rGDnpgK05UmCBDHpO9aIvxFu3b4EMShHFyUk9WAJ'
host = '<http://node0:8000>'
def create_bucket():
s3 = boto3.resource('s3', endpoint_url=host, aws_access_key_id=access_key, aws_secret_access_key=secret_key)
bucket = s3.Bucket("ansheng")
bucket.create()
def list_buckets():
s3 = boto3.client('s3', endpoint_url=host, aws_access_key_id=access_key, aws_secret_access_key=secret_key)
response = s3.list_buckets()
for item in response['Buckets']:
print(item['CreationDate'], item['Name'])
if __name__ == '__main__':
create_bucket()
list_buckets()
执行脚本创建名为ansheng的bucket
$ python3 test.py
2021-04-20 04:01:06.952000+00:00 ansheng
其他脚本的示例请参考ceph-s3-examples
- 通过s3fs-fuse将s3挂载到本地测试
$ dnf install epel-release -y
$ dnf install s3fs-fuse -y
将密钥写入到配置文件中
$ echo A4F6G48RZDCDX0QUP2IR:rGDnpgK05UmCBDHpO9aIvxFu3b4EMShHFyUk9WAJ > ${HOME}/.passwd-s3fs
$ chmod 600 ${HOME}/.passwd-s3fs
创建挂载点
$ mkdir /mnt/s3
$ s3fs -o use_path_request_style -o url=http://node0:8000 ansheng /mnt/s3
$ df -h | grep s3
s3fs 256T 0 256T 0% /mnt/s3
文件写入测试
$ echo ping > /mnt/s3/pong
$ cat /mnt/s3/pong
ping
结束
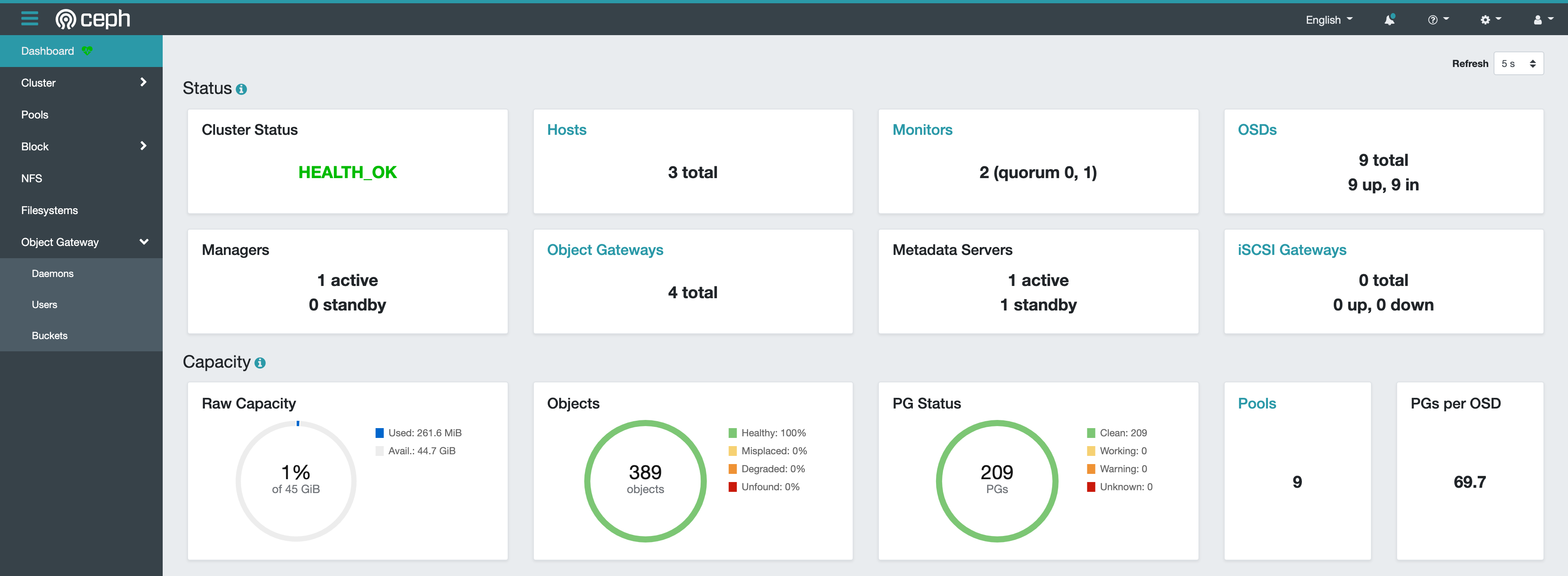
- 查看集群状态
$ ceph -s
cluster:
id: 523d520c-a179-11eb-b470-0800278a6302
health: HEALTH_OK
services:
mon: 2 daemons, quorum node0,node1 (age 2h)
mgr: node1.bvfakn(active, since 70m)
mds: 1/1 daemons up, 1 standby
osd: 9 osds: 9 up (since 2h), 9 in (since 2h)
rgw: 4 daemons active (2 hosts, 1 zones)
data:
volumes: 1/1 healthy
pools: 9 pools, 209 pgs
objects: 389 objects, 33 KiB
usage: 262 MiB used, 45 GiB / 45 GiB avail
pgs: 209 active+clean
- 查看DashBoard
注意,如果你是部署了多个mgr,需要通过ceph -s查看mgr运行在那个节点上,上面可以看到mgr运行在node1节点,所以我们打开node1节点的IP+PORT